 Static Model¶
Static Model¶
The static model describes what applications need to run, on which host and what it means to deploy and run an application. It is represented by a json document.
Structure of the model¶
The most basic structure of the model is the following:
{
"fabric": "glu-dev-1",
"metadata": {"name": "My Model"}
"agentTags": {},
"entries": []
}
Note
The model is internally represented by the SystemModel (groovy) class.
Table of possible values:
| Name | Required |
|---|---|
| agentTags | No |
| entries | No |
| fabric | Yes |
| metadata | No |
fabric¶
The fabric section is required and specifies which fabric this model is for. It is a simple string.
Note
if you have more than 1 fabric, you need to have 1 model for each one of them
metadata¶
This section is of type metadata and can contain any kind of information you want to store alongside your model. One way to think about it is structured comments. The console can be configured to display and/or use some of this information (TODO: add link)
Tip
The name entry will be used in the console in addition to the checksum of the model (if it is provided). It is strongly encouraged to give a unique name to a model so that it is easier to differentiate them in the console.
agentTags¶
This section contains tags that you want to assign to each entries that are deployed on this agent.
It is represented as map where:
- the key is the name of an agent
- the value is an array of tags (a tag is a string)
Example:
"agentTags": {
"agent-1": ["small-instance", "osx"],
"agent-2": ["large-instance", "linux"]
},
Tip
agentTags are no more than a shortcut to assign the same set of tags to all entries assigned to the agent (see tags)
entries¶
This section is an array of entries. An entry describes where a particular instance of an application need to be deployed, and how to deploy it. An entry is represented like this in json:
{
"agent": "node01.prod",
"mountPoint": "/search/i001",
"script": "http://repository.prod/scripts/webapp-deploy-1.0.0.groovy",
"initParameters": {},
"entryState": "running",
"parent": "/",
"metadata": {},
"tags": []
}
Note
An entry is internally represented by the SystemEntry (groovy class).
Tip
If you check glu Script Engine, you will be able to understand better why an entry is defined this way:
- agent represents which agent to talk to
- mountPoint, script, parent and initParameters are the parameters provided to the installScript api
Note
tags are only used in the console
Table of possible values:
| Name | Required |
|---|---|
| agent | Yes |
| entryState | No |
| initParameters | No |
| metadata | No |
| mountPoint | Yes |
| parent | No |
| script | Yes |
| tags | No |
agent¶
This section describe on which agent the application needs to be installed.
Note
This has to be the name of the agent as defined by Fabric & Agent name. In most cases the name of the agent is the hostname, but since it is configurable, it may be different. This is so that it is possible to start more than one agent on a single node (which is very useful for development purposes).
mountPoint¶
The mount point represents a unique key on the agent. You can reuse the same value for a different agent.
Tip
This value is predominently displayed in the console so in general it is better to give it a very meaningful value. For example /search/i001 describes the fact that it is the search application, instance 001. You are of course free to use whichever convention you would like.
script¶
This section should be a URI pointing to the glu script that will be used to deploy the application.
initParameters¶
This section describes the initialization parameters that are going to be provided to the script. It is of type metadata and can contain whatever values you want to provide to the script. Example:
"initParameters": {
"container": {
"skeleton": "http://repository.prod/tgzs/jetty-7.2.2.v20101205.tgz",
"config": "http://repository.prod/configs/search-container-config-2.1.0.json",
"port": 8080
},
"webapp": {
"war": "http://repository.prod/wars/search-2.1.0.war",
"contextPath": "/",
"config": "http://repository.prod/configs/search-config-2.1.0.json"
}
}
Tip
The values you use in this section are used to compute the delta! This is how the orchestration engine determines that an application needs to be upgraded (because the version has changed)!
parent¶
This section is optional and will default to / if not provided. The value must be pointing to another mountPoint on the same agent. You use it for defining a parent/child relationship between 2 entries.
In the tutorial (and in the example above), we have 1 entry defining a webapp container and its webapp(s). When defined this way, it means that whenever you take an action on the entry (deploy, bounce, etc...) it affects the entire container and webapps. It may or may not be the desired effect. By using the parent/child relationship you can decouple the actions while still maintaining the fact that it does not make sense to deploy a webapp without its container! Example:
"entries": [
{
"agent": "agent-1",
"mountPoint": "/container",
"script": "http://repository.prod/scripts/webapp-container-1.0.0.groovy",
"initParameters": {
"skeleton": "http://repository.prod/tgzs/jetty-7.2.2.v20101205.tgz",
"config": "http://repository.prod/configs/search-container-config-2.1.0.json",
"port": 8080
}
},
{
"agent": "agent-1",
"mountPoint": "/webapp1",
"parent": "/container",
"script": "http://repository.prod/scripts/webapp-1.0.0.groovy",
"initParameters": {
"war": "http://repository.prod/wars/search-2.1.0.war",
"contextPath": "/",
"config": "http://repository.prod/configs/search-config-2.1.0.json"
}
}
],
In this example, you can see how the 2 entries are defined, the second one defining a parent section pointing to the other entry. By defining it this way, the child (or children) can be independently upgraded without ever restarting the container (which may be very useful if your container hosts multiple webapps).
Note
You are not limited to one child! You can have as many as you want.
Tip
Another example of the parent/child relationship usage would be an OSGi container (parent) and its bundles (children).
Warning
Make sure to read the parent script requirements in the “Parent Script” section.
entryState¶
This section defines in which state (of the state machine) it should be deployed at. By default, it is set to running (this field is optional and most of the time you don’t need to enter a value). Other valid states for the (standard) state machines are installed and stopped.
Note
If you use entryState and parent the actual state may defer from what you express as the children needs to be taken into account for the computation of the actual desired state.
metadata¶
This section is of type metadata and can contain any kind of information you want to store alongside this entry. The model itself also has a metadata section but this one is specific to the entry and each entry can have its own. The console can be configured to display and filter on metadata (TODO add link).
Note
unlike the initParameters section, metadata is not used to compute the delta.
Tagging¶
The static model has 2 ways of defining tags:
- through agentTags for the entire model
- through tags for a particular entry
What is a tag?¶
A tag is a simple piece of information (a simple string) that can be associated to an entity. You may be familiar with the concept under a different name: label. There are lots of system using this concept. For example, gmail allows you to associate any number of labels to an email (thus simulating folders but more powerfull because the email can be in more than one folder!).
Example of tags: frontend, backend, linux, cluster-search-1, cluster-seach-2, ...
Why would you use tags?¶
As you saw in the previous sections, the system model is a rather flat structure: a simple array of entries. It was actually designed this way on purpose because glu does not want to impose how you want to model your system. For example, for some, a cluster means something, for others it means something different.
Tags allow you to add meaning to the model that glu does not know about (and does not have to) (for glu cluster means nothing :). Tags are then used in very powerful ways:
- display: the console displays tags (you can actually configure the color (TODO add link))
- filtering: there is an entire section about filtering and how it works but quickly speaking it allows you to constraint glu on what to do. For example, you can tell glu to bounce all applications that are part of the first search cluster running on linux nodes.
What about metadata?¶
metadata are very similar to tags with the only difference that metadata are structured. The console can also display metadata (albeit not like tags), and use it for filtering. In general, metadata is more heavyweight than tags so if you have a choice, you should use tags.
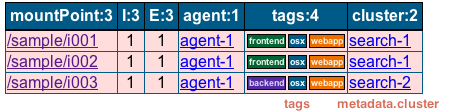
Example:
// Expressing the same information
// using metadata
{
"metadata": {
"cluster": "search-1",
"application": {
"kind": "webapp"
}
}
}
// using tags
{
"tags": ["cluster-search-1", "webapp"]
}
Note
As you can see in the filtering section, expressing filters with tags is simpler and can result in faster results.
Json Groovy DSL¶
The json groovy dsl uses the convenience of groovy to express the model: instead of defining the model in one chunk, you build it pieces at a time which makes it a lot easier to build and read. You can also use the power of groovy, like variable replacements (${xxx}) syntax, loops, iterations, if conditions, etc...
Tip
This syntax is for convenience only. Once you load the model in the console it will be expanded in full json.
Here are the top entries of the dsl:
id
fabric
name
metadata
entries
agentTags
Note
It is not recommended to define the id and it is better to let glu compute it for you.
Check the repository for examples on how to use the dsl.