 Agent¶
Agent¶
The glu agent is an active process that needs to run on every host where applications need to be deployed. Its main role is to run glu scripts. It is the central piece of the deployment automation platform and is the only required piece of infrastructure. It exposes a REST api and a command line (which invokes the REST api under the cover).
Fabric & Agent name¶
An agent belongs to one and only one fabric (which is a group of agents). The agent needs to have a unique name within a fabric which by default is the canonical host name of the computer the agent is running on. You can change the agent name and the fabric when you start the agent (-n and -f options respectively).
glu Script Engine¶
The agent is a glu script engine: it knows how to install and execute a glu script. You can check the agent api to view all the actions offered by the agent.
Installing a glu script¶
Installing a glu script, which in the end is just a piece of code, essentially means that the agent will fetch it and instantiate it. This operation is synchronous and will succeed if and only if:
- the agent could locate and fetch the code
- the agent could instantiate the code (valid groovy class)
- the key (mount point) is really unique
Groovy API:
agent.installScript(mountPoint: "/geo/i001",
scriptLocation: "http://host:port/glu/MyGluScript.groovy",
initParameters: [skeleton: "ivy:/skeleton/jetty/1.0"])
Command Line:
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -i http://host:port/glu/MyGluScript.groovy \
-a "[skeleton: 'ivy:/skeleton/jetty/1.0']"
REST API:
PUT /mountPoint/geo/i001
{"args": {"scriptLocation": "http://host:port/glu/MyGluScript.groovy",
"initParameters": {"skeleton": "ivy:/skeleton/jetty/1.0"} } }
- A glu script gets installed on a given mount point which is the unique key that the following commands will use to reference it.
- The script location is a URI which points to the location of the script (this URI must obviously be accessible from the agent, so although you can use a URI of the form file://, it will work only if the file can be accessed (ex: local filesystem or nfs mounted file system)).
- initParameters is of type metadata and is a map that the agent will make available when executing the glu script
Note
check the javadoc for more details on the API
Executing a glu script action¶
Once the script is installed, you can execute actions on it. Executing an action is fundamentally an asynchronous operation but some convenient api calls are provided to make it synchronous.
With no arguments¶
Groovy API:
// non blocking call
agent.executeAction(mountPoint: "/geo/i001", action: "install")
// blocking until timeout
agent.waitForState(mountPoint: "/geo/i001", state: "installed", timeout: "10s")
Command Line:
# non blocking
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -e install
# blocking until timeout
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -e install -w installed -t 10s
# which can be run as 2 commands
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -e install
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -w installed -t 10s
# Shortcut for installscript + install + wait for state
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -I http://host:port/glu/MyGluScript.groovy \
-a "[skeleton:'ivy:/skeleton/jetty/1.0']" -t 10s
REST API:
// executeAction
POST /mountPoint/geo/i001
{"args": {"executeAction": {"action": "install"} } }
// wait for state
GET /mountPoint/geo/i001?state=installed&timeout=10s
You can execute any action on the script that you are allowed to execute (as defined by the state machine). Note that you use the same mount point used when installing the script. If you are not allowed then you will get an error: for example, using the default state machine you cannot run the start action until you run install and configure. The command line has a shortcut to do all this in one command:
Tip
Command Line shortcut:
# Shortcut for installscript + install + wait for state + configure + wait for state +
# start + wait for state
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -S http://host:port/glu/MyGluScript.groovy \
-a "[skeleton:"ivy:/skeleton/jetty/1.0"]"
With arguments¶
You can also provide parameters to the action when you invoke it:
Groovy API (with action args):
// non blocking call
agent.executeAction(mountPoint: "/geo/i001", action: "install" actionArgs: [p1: "v1"])
Command Line (with action args):
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -e install -a "[p1: 'v1']"
REST API (with action args):
// executeAction
POST /mountPoint/geo/i001
{"args": {"executeAction": {"action": "install", "actionArgs": {"p1": "v1"} } } }
They are then available through the normal groovy closure invocation functionality:
class MyGluScript {
def install = { args ->
if(args.p1 == "v1")
{
// do something
}
}
}
Uninstalling the script¶
Once you are done with the script, you can uninstall it.
Groovy API:
agent.uninstallScript(mountPoint: "/geo/i001")
Command Line:
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -u
REST API:
DELETE /mountPoint/geo/i001
Note
you cannot uninstall the script unless the state machine allows you do to so. If you are in state running you first need to run stop, unconfigure and uninstall. There is a way to force uninstall irrelevant of the state of the state machine:
Force uninstall¶
Groovy API (force uninstall):
agent.uninstallScript(mountPoint: "/geo/i001", force: true)
Command Line (force uninstall):
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -u -F
REST API (force uninstall):
DELETE /mountPoint/geo/i001?force=true
Tip
The command line also has a shortcut to uninstall by properly running through all the phases of the state machine: Command Line (shortcut):
agent-cli.sh -s https://localhost:12906/ -m /geo/i001 -U
Capabilities¶
One of the main design goals in building the agent was the ability to write simple glu scripts. This is achieved with the fact that the agent enhances the glu scripts with capabilities that make it easier to write them. Most of the capabilities are made available to the glu scripts by ‘injecting’ properties that the glu scripts can simply reference (under the hood it uses groovy MOP capabilities).
Tip
Implicitely (at runtime), all glu scripts implement the GluScript interface.
log¶
The log property allows you to log any information in the agent log file. It is an instance of org.slf4j.Logger:
def configure = {
log.info "this is a message logged with info level"
log.debug "this message will be logged only if the agent is started with debug messages on"
}
params¶
Every glu script action has access to the initParameters provided at installation time through the params property:
def configure = {
log.info "initParameters = ${params}"
}
mountPoint¶
The mountPoint on which the script was installed. In general, this property is used to install the application in a unique location (since the mountPoint is unique):
def install = {
log.info "mountPoint = ${mountPoint}"
def skeleton = shell.fetch(params.skeleton) // download a tarball
shell.untar(skeleton, mountPoint) // will be unzipped/untarred in a unique location
}
parent¶
This property contains the GluScript of the parent (for root this value is null). This property is to be used by a child when it wants to invoke methods on its parent.
children¶
This property contains a collection of GluScript of the children of this script. This property is to be used by a parent when it wants to invoke methods on its children.
stateManager¶
An instance of org.linkedin.glu.agent.api.StateManager (StateManager api) which allows to access the state:
def install = {
log.info "current state is ${stateManager.state}"
}
shell¶
An instance of org.linkedin.glu.agent.api.Shell (Shell api) which gives access to a lot of shell like capabilities
file system (see org.linkedin.groovy.util.io.fs.FileSystem (FileSystem api) like ls, cp, mv, rm, tail...
process (fork, exec...)
fetch/untar to download and untar/unzip binaries (based on any URI):
def install = { def skeleton = shell.fetch(params.skeleton) // download a tarball shell.untar(skeleton, mountPoint) // unzip/untar (detect zip automatically) shell.rm(skeleton) }Tip
The agent handles zookeeper:/a/b/c style URIs and can be configured to handle ivy:/a/b/1.0 style URIs.
rootShell¶
The difference between rootShell and shell is where / is referring to. In the case of shell, / refers to the application directory (see GLU_AGENT_APPS config property). In the case of rootShell, / refers to the root of the filesystem.
Tip
it is highly recommended to install your applications relative to shell using a pattern like this:
def installRoot = shell.toResource(mountPoint)
glu will automatically clean after yourself on uninstall if you use this pattern. Using rootShell is not recommended but still provided in the (hopefully rare) cases when you need it.
shell.env¶
shell.env is a map which allows you to access all the configuration properties used when the agent booted including the ones stored in zookeeper. This allows for example to configure fabric dependent behavior. If you store the property:
my.company.binary.repo.url=http://mybinaryrepo:9000/root
in the configuration file (agent config) loaded in ZooKeeper for a given fabric then your scripts can use relative values:
shell.fetch("${shell.env['my.company.binary.repo.url']/${params.applicationRelativePath}"}
timers¶
An instance of org.linkedin.glu.agent.api.Timers (Timers api) which allows you to set/remove a timer (for monitoring for example):
def timer1 = {
log.info "hello world"
}
def install = {
// the closure timer1 will be executed every minute
timers.scedule(timer: timer1, repeatFrequency: "1m")
}
def uninstall = {
timers.cancel(timer: timer1)
}
Tip
The frequency for a timer is of type org.linkedin.util.clock.Timespan (Timespan api) and is expressed as a string:
15s // 15 seconds
1m10s // 1 minute 10 seconds
Integration with ZooKeeper¶
The agent will automatically export to ZooKeeper, any field declared in a glu script. Those fields will then be available from the console or the REST api. You can see it in action in the following screenshot (in the scriptState/script section):
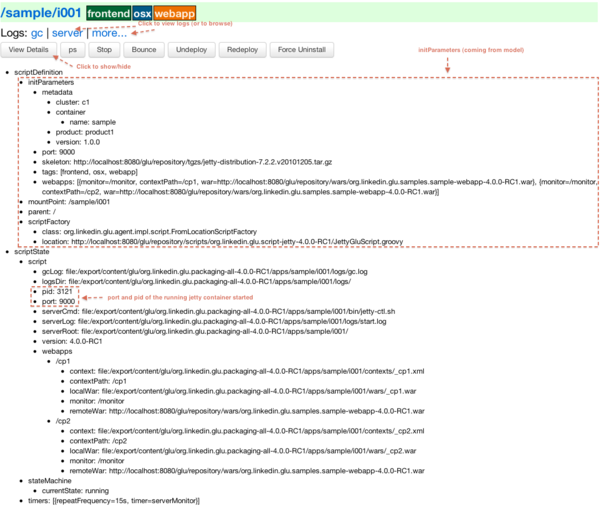
To produce this output, the glu script is defined this way:
class JettyGluScript
{
// the following fields represent the state of the script and will be exported to ZooKeeper
// automatically thus will be available in the console or any other program 'listening' to
// ZooKeeper
def version = '2.2.0'
def serverRoot
def serverCmd
def logsDir
def serverLog
def gcLog
def pid
def port
def webapps
...
In order for a field to be declared exportable it must follow the following rules:
it must be a Serializable field (so any primitive or collection / map will work)
it must be representable as a JSON object
Note
Not all java Serializable objects can be represented as a JSON object!
it must not be declared transient
Tip
If you do not want to export your field, simply mark it transient:
class MyScript {
transient def nonExported // this field won't be exported
}
Note
If you shutdown and restart the agent, the fields in your script will be restored to their last known value before shutdown if and only if the field was exportable, or in other words, if you declare your field transient its value won’t be preserved accross restart!
In addition, the ZooKeeper connection used by the agent is exported via the agentZooKeeper glu script property. This property is of type org.linkedin.zookeeper.client.IZKClient and lets you read and write whatever data you want in ZooKeeper.
Warning
The agent will not cleanup any data stored using agentZooKeeper when the script is uninstalled! Make sure you do your own cleanup (usually in the uninstall phase).
OS level functionalities¶
The agent also offers some OS level functionalities
ps / kill¶
Groovy API:
agent.ps()
agent.kill(12345, 9)
Command Line:
agent-cli.sh -s https://localhost:12906/ -p
agent-cli.sh -s https://localhost:12906/ -K 1234/9
REST API:
// ps
GET /process
// kill -9 1234
PUT /process/1234
{"args": {"signal": 9} }
tail / list directory content¶
Groovy API:
agent.getFileContent(location: "/tmp") // directory content
agent.getFileContent(location: "/tmp/foo", maxLine: 500) // file content (tail -500)
command line:
agent-cli.sh -s https://localhost:12906/ -C /tmp
agent-cli.sh -s https://localhost:12906/ -C /tmp/foo -M 500
REST API:
GET /file/tmp
GET /file/tmp/foo?maxLine=500
REST API¶
TODO: add REST API
ZooKeeper¶
By default the agent uses ZooKeeper to ‘publish’ its state in a central location as well as to read its configuration. Note that it is optional and ZooKeeper can be disabled in which case the whole configuration needs to be provided.
Auto Upgrade¶
The agent has the capability of being able to upgrade itself.
Note
Since glu 5.1.0, the agent upgrade artifact is generated as part of the distribution generation step and can be found under <outputFolder>/agents/org.linkedin.glu.agent-server-<clusterName>-upgrade-<version> (simply tar this folder or use the --compress option when running the setup.sh command).
Using the command line¶
Command Line:
agent-cli.sh -s https://localhost:12906/ -c org.linkedin.glu.agent.impl.script.AutoUpgradeScript \
-m /upgrade -a "[newVersion:'2.0.0',agentTar:'file:/tmp/agent-server-upgrade-2.0.0.tgz']"
agent-cli.sh -s https://localhost:12906/ -m /upgrade -e install
agent-cli.sh -s https://localhost:12906/ -m /upgrade -e prepare
agent-cli.sh -s https://localhost:12906/ -m /upgrade -e commit
agent-cli.sh -s https://localhost:12906/ -m /upgrade -e uninstall
agent-cli.sh -s https://localhost:12906/ -m /upgrade -u
Using the console¶
Click on the Admin tab, then Upgrade agents.
Independent lifecycle¶
The agent can be started / stopped independently of the applications that it is managing: the agent stores its state locally (and in ZooKeeper if enabled) and knows how to restore itself properly (including restarting any timers that were scheduled by glu scripts!)
Requirements¶
The glu agent requires java 1.6 to be installed on the host it is running on. As this stage only unix like hosts are supported (tested on Solaris and Mac OS X).
Agent configuration¶
The agent uses the configuration mechanisms offered by the meta model.
Configuration properties¶
The properties defined with an environment variable can be set in the meta model this way:
agents << [
...,
configTokens: [
'JVM_SIZE': '-Xmx128m',
... etc ...
]
],
The properties defined with a java property (only) variable can be set in the meta model this way (simply remove glu.agent from the name of the property) (check the template):
agents << [
...,
configTokens: [
'scripts.sharedClassLoader': true,
... etc ...
]
],
| Opt | Env. | Java Property | Default | Explanation |
|---|---|---|---|---|
| NA | GLU_CONFIG_PREFIX | NA | glu | Prefix used in all system properties below |
| -z | GLU_ZOOKEEPER | glu.agent.zkConnectString | Undefined but required! | Connection string to ZooKeeper Note Set for you automatically based on information in meta model |
| -n | GLU_AGENT_NAME | glu.agent.name | Canonical hostname | Name of the agent (this property is very important because this is how you refer to an agent in glu!) |
| -t | GLU_AGENT_TAGS | glu.agent.tags | Undefined (optional) | Tags for this agent |
| -c | GLU_AGENT_HOSTNAME_FACTORY | glu.agent.hostnameFactory | :ip | Determine how the property glu.agent.hostname will be computed: it can take the following values:
|
| NA | GLU_AGENT_PORT | glu.agent.port | 12906 | The port the agent will listen on (REST api port) |
| NA | GLU_AGENT_ADDRESS | glu.agent.address | Undefined (optional) | The address the agent will bind to (REST api address) |
| -f | GLU_AGENT_FABRIC | glu.agent.fabric | Undefined (read from ZooKeeper by default) | The fabric this agent belongs to |
| NA | GLU_AGENT_APPS | glu.agent.apps | $GLU_AGENT_HOME/../apps | The root of a directory where the applications deployed by glu will be installed. Note the agent must have write permission to this folder! |
| NA | GLU_AGENT_ZOOKEEPER_ROOT | glu.agent.zookeeper.root | /org/glu | The root path for everything written to ZooKeeper Note use zooKeeperRoot in the meta model instead which will change it where needed appropriately. |
| NA | APP_NAME | org.linkedin.app.name | org.linkedin.glu.agent-server | This parameter is used mostly to distinguish the process running and is not used by the agent per se |
| NA | APP_VERSION | org.linkedin.app.version | <version of the agent> | This parameter is used mostly to distinguish the process running and is not used by the agent per se |
| NA | JVM_CLASSPATH | NA | set by the ctl script | Classpath for the agent |
| NA | JVM_SIZE | NA | -Xmx128m | Java VM size |
| NA | JVM_SIZE_NEW | NA | Undefined | New Generation Sizes (-XX:NewSize -XX:MaxNewSize) |
| NA | JVM_SIZE_PERM | NA | Undefined | Perm Generation Sizes (-XX:PermSize -XX:MaxPermSize) |
| NA | JVM_GC_TYPE | NA | Undefined | Type of Garbage Collector to use |
| NA | JVM_GC_OPTS | NA | Undefined | Tuning options for the above garbage collector |
| NA | JVM_GC_LOG | NA | -XX:+PrintGCDateStamps -Xloggc:$GC_LOG | JVM GC activity logging settings ($LOG_DIR set in the ctl script) |
| NA | JVM_LOG4J | log4j.configuration | file:$CONF_DIR/log4j.xml | log4j configuration (logging output/error for the agent) |
| NA | JVM_TMP_DIR | java.io.tmpdir | $GLU_AGENT_HOME/data/tmp | temporary folder for the glu agent |
| NA | JVM_XTRA_ARGS | NA | all other values combined | directly set to the java command line |
| NA | JVM_DEBUG | NA | -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket, address=8887, server=y, suspend=n | Debug arguments to pass to the JVM (when starting with -d flag) |
| NA | JVM_APP_INFO | NA | -Dorg.linkedin.app.name=$APP_NAME -Dorg.linkedin.app.version=$APP_VERSION | Appears as command line arguments |
| NA | MAIN_CLASS | NA | org.linkedin.glu.agent.server.AgentMain | Main java class to run |
| NA | MAIN_CLASS_ARGS | NA | file:$CONF_DIR/agentConfig.properties | The config file for the bootstrap (see Agent configuration) |
| NA | JAVA_HOME | NA | Undefined but required | Must be set to the location of java |
| NA | JAVA_CMD | NA | $JAVA_HOME/bin/java | The actual java command |
| NA | NA | glu.agent.scriptRootDir | ${glu.agent.apps} | See GLU_AGENT_APPS |
| NA | NA | glu.agent.dataDir | ${glu.agent.homeDir}/data | the directory where the data (non version specific) is stored |
| NA | NA | glu.agent.logDir | ${glu.agent.dataDir}/logs | the log directory |
| NA | NA | glu.agent.tempDir | ${glu.agent.dataDir}/tmp | This is the temporary directory for the agent |
| NA | NA | glu.agent.scriptStateDir | ${glu.agent.dataDir}/scripts/state | Contains the state of the scripts (when the agent shutdowns/reboots, it can recover the state) |
| NA | NA | glu.agent.rest.nonSecure.port | 12907 | This port is used when no ZooKeeper is specified so that the console can tell the agent where is its ZooKeeper (TODO: explain this in another section) |
| NA | NA | glu.agent.persistent.properties | ${glu.agent.dataDir}/config/agent.properties | All values set are remembered from one run to another so that you don’t have to specify them over and over |
| NA | NA | glu.agent.zkSessionTimeout | 5s | Timeout for ZooKeeper |
| NA | NA | glu.agent.configURL | ${glu.agent.zookeeper.root}/agents/fabrics/ ${glu.agent.fabric}/config/config.properties | The location of (more) configuration for the agent (default to a fabric dependent location in ZooKeeper). |
| NA | NA | glu.agent.sslEnabled | true | Whether the REST api should be exported over https or not |
| NA | NA | glu.agent.keystorePath | zookeeper:${glu.agent.zookeeper.root}/agents /fabrics /${glu.agent.fabric}/config /agent.keystore | Location of the keystore which contains the private key of the agent |
| NA | NA | glu.agent.keystoreChecksum | Must be computed | Checksum for the keystore |
| NA | NA | glu.agent.keystorePassword | Must be computed | Password for the keystore |
| NA | NA | glu.agent.keyPassword | Must be computed | Password for the key (inside the keystore) |
| NA | NA | glu.agent.truststorePath | zookeeper:${glu.agent.zookeeper.root}/agents /fabrics /${glu.agent.fabric}/config /console.truststore | Location of the trustore which contains the public key of the console |
| NA | NA | glu.agent.truststoreChecksum | Must be computed | Checksum for the truststore |
| NA | NA | glu.agent.truststorePassword | Must be computed | Password for the truststore |
| NA | NA | glu.agent.features.commands.enabled | true | enable/disable the commands feature |
| NA | NA | glu.agent.commands.storageType | filesystem (only supported value right now) | type of storage for commands |
| NA | NA | glu.agent.commands.filesystem.dir | ${glu.agent.dataDir}/commands | root dir for commands storage |
| NA | NA | glu.agent.scripts.sharedClassLoader | false | use shared class loader for scripts |
Tip
The number of configuration properties may seem a little bit overwhelming at first but most of them have default values. Furthermore, the Step 4: Generate the distributions [-D] phase sets the only required property for you (which is the location of its ZooKeeper cluster)!
Installation¶
Check the section Step 5: Install the distributions for details about how to install the agent the first time.
Once the agent is installed, you can simply use the auto upgrade capability to upgrade it.
Security¶
The agent offers a REST API over https, setup with client authentication. In this model, what is really important is for the agent to allow only the right set of clients to be able to call the API.
Note
Although this is not recommended for a production setup, you may be ok in using http in which case simply define:
def keys = null
in your glu meta model.
Key setup¶
The keys needed by the agent are generated during the keys generation step.
Multiple agents on one host¶
You can run multiple agents on the same machine as long as you assign them different ports and different names although it is not recommended for production. This is usually used in development.