Configuring glu¶
glu is very configurable and offers many different approaches for configuring it:
- simple tweaks like port numbers in the meta model
- more advanced tweaks, like jvm parameters, in the meta model (configTokens sections)
- config templates which lets you add/delete/modify any file in the distributions that will be generated during setup
- console plugins to extend/modify the behavior of the console
Tip
Although glu offers many configuration points, the defaults are usually sensible and you should be good without tweaking anything until there is a specific need.
Configuration concepts¶
Note
These concepts are new since glu 5.1.0. If you are using a prior version of glu, the configuration is mostly manual. The documentation that comes bundled with glu has more details.
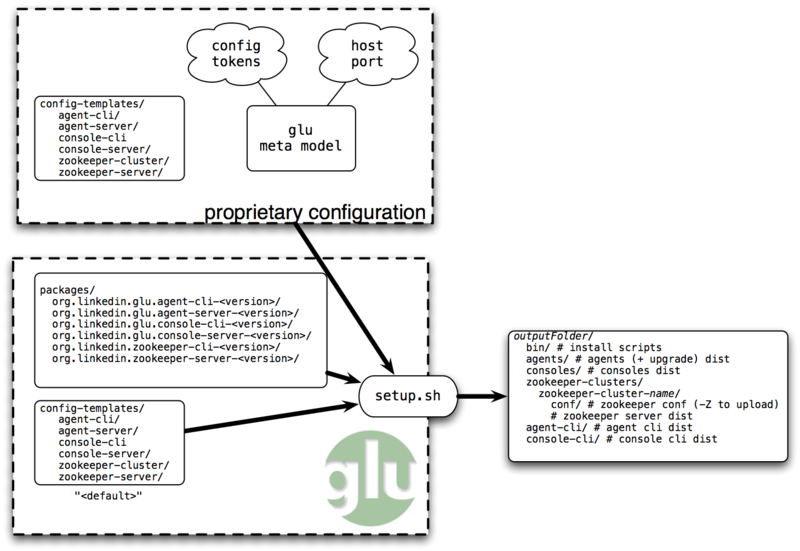
- glu comes bundled with several components (clis and servers) distributed as raw packages under the packages/ top folder.
- glu also comes bundled with a tool (setup.sh), that is used as part of the setup process to generate the distributions (which are ready to install/run packages).
- In order for the setup tool to generate the right set of packages tailored for your environment, you need to define, at the very least, a glu meta model which essentially describes where each component needs to go (on which host they are installed).
- In addition, the meta model lets you tweak several configuration parameters if the default ones are not satisfactory.
- The setup tool also lets you provide additional templates to further tweak what goes inside the distributions (for example, you can replace the glu logo with your own, substitute a library with another one, change any startup script, etc...).
Understanding the setup workflow¶
When you generate the distributions (Step 4: Generate the distributions [-D]), this is what happens:
- the glu meta model is parsed to build an in-memory representation of the model
- based on information in the glu meta model, for each raw package
- the package is copied under the outputFolder (with the proper naming)
- each template in the config-templates folder(s) for this package is processed (this step uses information coming from the meta model including config tokens) and the resulting file is copied under the proper destination in the distribution.
- if requested, the distribution is compressed (.tgz)
Note
config templates are explained later, but the simplest template is simply a regular file that needs to be copied as-is in the distribution.
config-templates folder¶
A config-templates folder is simply a directory with a structure like this:
agent-cli/
agent-server/
console-cli/
console-server/
zookeeper-cluster/
zookeeper-server/
Tip
Every single directory in the config-templates folder (and recursively) is optional. So if you simply want to tweak the console server distribution, then you only need to create a console-server top folder.
Each top folder mimics the directory structure of a package and contains templates. For example:
agent-cli/
conf/
readme.txt
represents a valid config-templates folder. The resulting agent-cli distribution will contain the file readme.txt under the conf folder.
Note
The folder structure can contain some replacement tokens:
console-server/
@jetty.distribution@/
conf/
glu/
keys/
Config templates¶
A template is a file that lives in a config-templates. The exact location of the template file in the directory struture represents the location where the (processed) template will end up in the distribution. There are 4 kinds of templates each processed with different rules (ordered from simplest to most sophisticated):
- no specific extention (ex: readme.txt) => the file will simply be copied with no processing. This is perfect if you want to simply add/override files in the final distribution (like the glu logo, etc...).
- the file ends with .xtmpl (ex: readme.txt.xtmpl) => the file will be processed with simple token replacements (@xxxx@ syntax). This is perfect if you have simple static tokens to replace.
- the file ends with .gtmpl (ex: readme.txt.gtmpl) => the file will be processed through the groovy template engine (similar to .gsp files): you can have loops, if conditions, and the meta model is always accessible. This is perfect if you need to decide on values based on the meta model itself.
- the file ends with ctmpl (ex: readme.txt.ctmpl) => the file will be interpreted as a groovy code template, meaning it will be executed as a script (very similar concept to glu scripts!) with a shell variable and a toResource variable pointing to the final location of the file. This is usually used for more advanced use cases when the other kinds of templates do not work (for example if you want to delete files and/or folders from the distribution).
Tip
glu comes with a set of default templates (under packages/org.linkedin.glu.packaging-setup-<version>/config-templates) that are a good starting point.
Tip
If a template has the executable bit set (+x), it will be preserved after processing/copying.
Tip
The concept of templates is also available directly in your glu script with the shell.processTemplate call.
Providing your own config-templates¶
Although you can certainly tweak the config templates that comes bundled with glu, it is not recommended. Every version of glu will come with its set of templates which may change from time to time. This is why it is better to define your own set of config templates outside of the glu distribution and invoke the setup command this way:
setup.sh --config-templates-root "<default>" --config-templates-root /path_to_your_own_configs_root
Note
The order is important: the parameter "<default>" instructs the setup process to use the built-in config templates first, then use your own templates second.
configTokens¶
The config templates are processed with config tokens which are simple maps of key/value pairs. The key is always a String and the value needs to be a valid json type. They are defined in the glu meta model.